Symbolic Expression Graph
The Data Structure Encoding Program Dependencies
Clearblue views a program through the lens of its dependencies information. Intuitively, given a variable v and a location L in the program, we would like to answer two critical questions:
v at L?L?With the dependency view, Clearblue naturally supports a wide range of applications efficiently: (1) Users can model the flows of their cared variables in the program and track the conditions, i.e., the taken conditional branches, for such flows. (2) Users work on a dependency slice of their cared variables instead of the whole program, which is much more efficient.
Consider the following code:
string callee(Object obj) {
return obj.data();
}
void caller() {
Object a = ...
...
if (𝜑)
Object b = a;
...
print(callee(b));
}
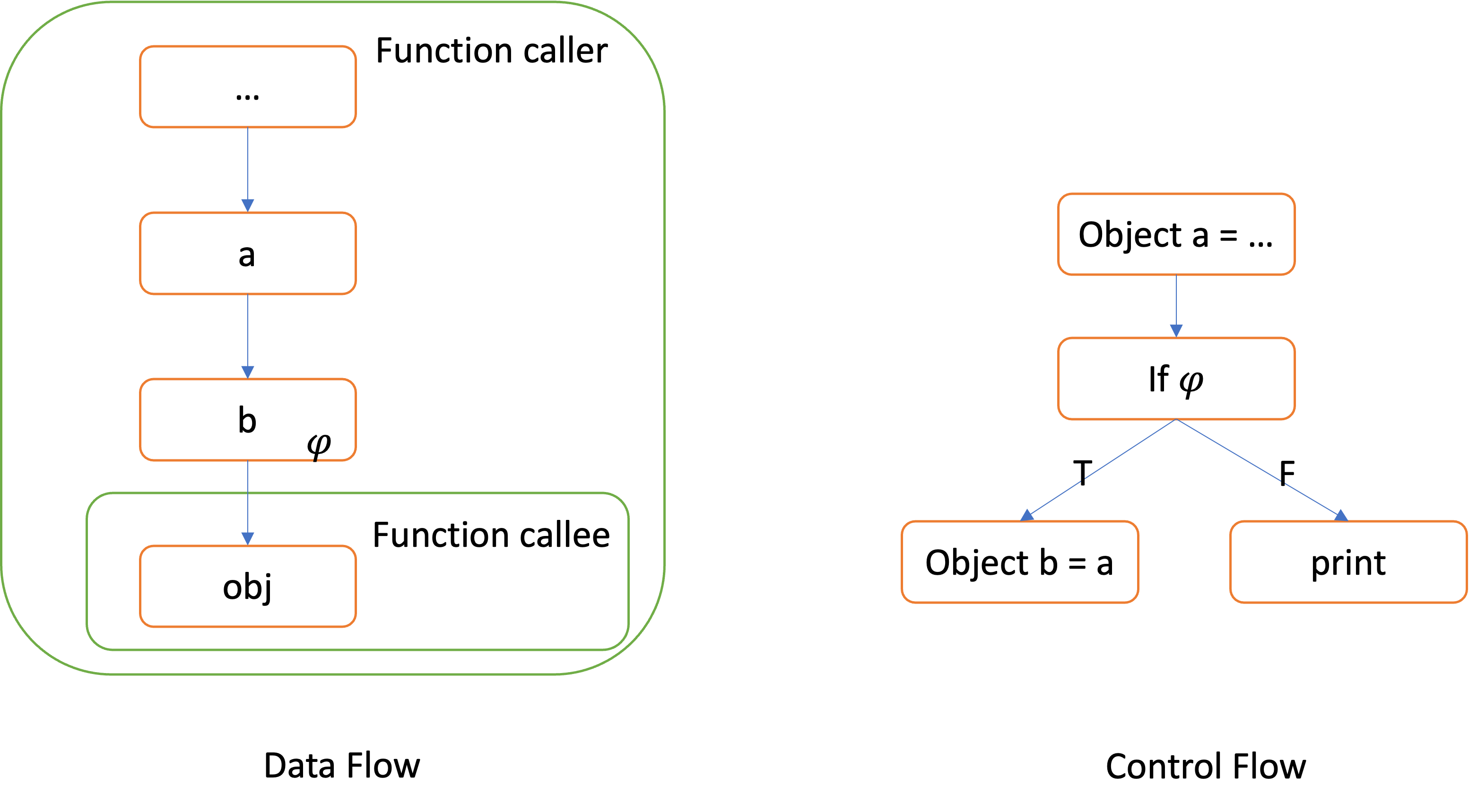
The related dependencies for the variable obj of the function callee are as follows:
Data dependency: obj is data dependent on b (as the call to callee passes b as the value for obj), while b is data dependent on a (as the assignment b = a passes the value of a to b).
Control dependency: b is control dependent on 𝜑, because the value of 𝜑 can determine wheter the true branch of the if statement will be executed.
By combining data and control dependencies, we gain a succinct yet expressive representation of how the concerned values propagate through the program. For instance, if a were initialized to NULL, we can infer from the program dependencies that a Null Pointer Dereference error may occur inside callee if the condition 𝜑 is met.
string callee(Object obj) {
return obj.data();
}
void caller() {
Object a = ...
Object c = ...
...
if (𝜑) {
Object b = a;
print(callee(b)); // (1)
} else {
Object d = c;
print(callee(d)); // (2)
}
...
}
In general, any problem of program analysis is faced with the tradeoff between precision and efficiency. The two questions regarding program dependencies could be handled with varied level of precision, which we illustrate using the slightly changed code example above:
(Path sensitivity) There exists two different “flows” of values for the variable obj, i.e., p1 = a->b->obj and p2 = c->d->obj,
which correspond to two different execution paths in the program. A path-sensitive analysis not only infers that {a,c} may flow to obj, but also knows the paths p1-p2 taken for {a,c} to flow into obj.
(Context sensitivity) Both p1 and p2 consist of a statement calling the function callee, but at different locations (1) and (2), which we refer to as call sites. A context-sensitive analysis will treat different call sites to the same callee function differently.
(Memory / Pointer indirection) Apart from direct assignment such as b=a (direct data dependencies), values in the program can flow through memory loads and stores such as *p = a; b = *p (indirect data dependencies). Clearly, the precision for resolving memory indirection can greatly affect the precision of dependencies analysis.
Improving the analysis precision in the above three aspects is highly beneficial for the clients, but can lead to significant overhead.
Clearblue designs a path-sensitive, context-sensitive dependency analysis with highly precise pointer reasoning, while capable of efficiently scaling to codebases of million lines of code. The sweet spot in the precision-efficiency tradeoff is achieved by our central data structure: Symbolic Expression Graph (SEG).
For each function in the program, Clearblue adopts a separate graph termed Symbolic Expression Graph (SEG) to encode the program dependencies information of that function. Paired with a global call graph denoting the “caller-callee” relation among functions, the core engine of Clearblue translates program analysis problems into algorithms that access, traverse, and manipulate the SEGs.
Briefly, each node of the SEG denotes a value (including both scalar values and memory locations); each edge (u,v) denotes a “value flow” from u to v; each edge is labelled with a condition 𝜑 for encoding the control dependencies. The design goal of SEG is to efficiently support precise dependency analysis:
p1 and p2 above are 𝜑 and !𝜑 respectively.Espeically, SEG enodes arithmetic operations in the program. If the statement if (𝜑) ... were replaced by y=10; if (x > y+z) ...,
the condition x > y+z && y=10 for taking the true branch could be readily recovered from the SEG. Clearblue then check the feasiblity of the condition for a value flow path in achieving path-sensitivity.
Modular structure: Each function has its own SEG where special “pseudo variables” are introduced to represent inputs and outputs of the function. Internally, Clearblue analyzes a function callee and summarizes its behaviors as relations between the input and output variables. Such function summaries are utilized when analyzing any function caller that calls callee, where different call sites
results in different applications of the function summary to achieve context-sensitivity.
Pointer awareness: SEG encodes both the direct data dependencies and indirect data dependencies. Specifically, values contained in memory locations such as *ptr are represented with speical nodes in the SEG.
The core engine of Clearblue consists of two parts:
(1) Graph Builder: Clearblue manages the intricacies mentioned in the previous subsection and constructs SEGs for each function together with a global call graph. APIs to access and manipulate these graphs are exposed, upon which users can develop their own static analyses.
(2) Graph Traverser: Clearblue contains a vulnerability detection engine based on the SEG APIs in (1). The engine hides the details for searching value flow paths over the SEGs, constructing function summaries, checking path feasiblity, and reporting bugs. It exposes a checker registration framework that enables users to register new types of vulnerability to check into the engine. We defer the discussion for writing vulnerability checkers to later sections.
The following content will be divided into three parts:
First, we detail structure of SEG and how it encodes program dependencies effectively.
Second, we introduce the APIs of the call graph for querying inter-procedural call relation.
Finally, we introduce the APIs to access and manipulate the SEGs.
The Data Structure Encoding Program Dependencies
APIs to access and manipulate the Symbolic Expression Graph
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.